大语言模型分享 – 入门篇
以下大部分内容使用 LLM 生成,包括 OpenAI GPT,Google Bard, Claude等
入门篇
- 什么是 LLM、GPT
- 能做什么事情
- 有哪些平台,国内如何使用
- 有什么技巧
- LLM 与搜索引擎有什么区别
进阶篇
- 最强开源 LLM 的性能对比及演示
- LLaMA 1, LLaMA 2 介绍
- 中英双语大模型对比
高级篇
- 大模型与向量数据库结合实现私有文档问答检索
- 如何训练和调优自有模型
Hello ai, 先从 Prompt 开始
你是 LLM 领域的专家,负责给用户进行培训、答疑,解决在使用 LLM中遇到的问题。
我想给同事进行 LLM 的入门培训,主要讲解 LLM 和 GPT 的关系,当前最主要的 LLM 大模型有哪些,除了 OpenAI 之外还有哪些头部平台,他们分别有什么特点,能解决哪些问题。
请帮我列一下培训提纲,要求全面,由浅入深,并添加一定的讲解内容。
请用 Markdown 语法输出。
Prompt 是指指示大语言模型 (LLM) 执行任务的文本或代码。Prompt 可以是简单的,也可以是复杂的。简单的提示可能只是一个单词或短语,例如“写一首关于爱情的诗”或“翻译这个句子成法语”。复杂的提示可能包括多个步骤,例如“给我写一篇关于人工智能的文章,其中包括人工智能的定义、人工智能的优缺点以及人工智能的未来。”
Prompt 是使用 LLM 的重要组成部分。没有提示,LLM 就无法知道应该做什么。提示帮助 LLM 理解任务的目标,并生成正确的输出。
Prompt 的格式没有限制。它可以是任何形式的文本或代码。但是,一些好的提示的特点是:
- 明确:提示应该清楚地说明任务的目标。
- 简洁:提示应该尽可能简洁。
- 准确:提示应该是正确的,并且应该使用正确的术语。
- 相关:提示应该与 LLM 的训练数据相关。
使用 LLM 时,仔细选择提示非常重要。好的提示可以帮助 LLM 生成高质量的输出,而坏的提示可能会导致错误或令人困惑的输出。
GPT
GPT(Generative Pre-trained Transformer)是一种基于 Transformer 的语言模型,由 OpenAI 在 2018 年提出。GPT 通过预训练在大量文本数据上,学习到语言的结构和语义,从而能够在下游任务中实现较好的效果。
Transformer 是由 Google 在 2017 年提出的。Transformer 是一种基于注意力机制的神经网络模型,它在机器翻译任务上取得了当时最优的效果。Transformer 的提出标志着自然语言处理领域的一个重大突破,它开启了一种新的机器学习模型架构,并推动了自然语言处理技术的发展。
LLM
- LLM 是指大语言模型,是指在大量文本数据上训练的神经网络模型。
- LLM 可以生成文本、翻译语言、编写不同类型的创意内容,并以信息丰富的方式回答您的问题。
- LLM 仍在开发中,但它们已经学会了执行许多类型的任务,包括
- 生成文本
- 翻译语言
- 编写不同类型的创意内容
- 以信息丰富的方式回答您的问题
LLM 和 GPT 的关系
GPT 是 OpenAI 开发的大型语言模型,是 LLM 的一种。Google 开发了 Bard,百度发布了文心一言。
大语言模型能做什么
能力
- 一个掌握全行业知识的专家、顾问、助理
- 考试,写文章,写论文,写代码
- 理解文本内容,翻译、总结、预测
- 多模态模型可以将非结构化数据转成文本或者图像进行理解
- 上下文理解
- 法律解读
不足
- 计算能力拉胯,牺牲精度换广度
- 可能会一本正经的说瞎话
- 它偶尔可能会生成不正确或误导性的信息,或产生冒犯性或有偏见的内容
- 它无意提供专业建议,包括法律、财务和医疗建议,不要在没有进行自己的独立研究的情况下依赖和信任
风险
- 所有信息都可能会经过人工审核,涉及信息泄漏风险
- 在国内调用国外 LLM Api 实现的能力接入,在国内可能涉及数据跨境的违法行为
主要玩家
最优秀梯队
- GPT-4 – openai
- Claude-2 – anthropic
优秀梯队
- Claude-instant-v1
- GPT-3.5-turbo
开源梯队
- Vicuna-33B – meta
- Llama-2-70b-chat – meta + microsoft
总排行
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
国内如何使用
直接访问
访问界面,需要北美IP,香港的 IP 也不行
可以接入 Api,收费
第三方
推荐,往往有多个平台可以对比效果
有收费包,也有免费体验
- 无限 GPT-4 请求次数,国内可以使用,但不允许输入中文。
- 一个集成了多个 GPT 的平台,支持 GPT3.5,免费版本不限次数,国内无法使用。
- 一个集成了多个 GPT 的平台,支持 GPT3.5,GPT4,国内可以使用,浏览器插件非常好用
- Google 出的有实时数据的GPT,拥有最实时的数据,只有国外能用
使用技巧 prompt engineering
- 像人类一样沟通
- 提示词要完整、清晰、简洁、充分、不矛盾
- 分场景,如信息生成、回答问题、数据整合、方便交互、多段输入
https://www.bilibili.com/video/BV1AT41187qt/
https://github.com/datawhalechina/prompt-engineering-for-developers/tree/main/content
https://learnprompting.org/zh-Hans/
https://chatgpt-prompt-splitter.jjdiaz.dev/
“我想要系统学习 NLP 算法知识,请以表格的方式,为我输出一份每周学习计划”
“我想要写一份营销文案,请以海明威的语言风格,为我输出 google 网站营销文案”
“将段落 1,段落 2,段落 3 这些内容整合为一段 300 字左右的内容”;“将这篇文章压缩为 20 字以内的一句话”
“将我正在未一群企业家授课,讲解如何系统学习 AI 大模型知识,请为我制定一份演讲提纲,以及一系列的培训计划”
“我想要设计一组科幻题材的人物漫画,主要分为五个角色,请分别为我设计五组用于在 midjourney 生成图片的提示词”
“假设你是一名 500 强企业得面试官,请与我进行角色扮演,对我进行一次模拟面试,我回复 ok 后面试即开始”
LLM 与搜索引擎有什么区别
- 主要区别在于,LLM可以生成文字,而搜索引擎只能返回已存在的文本。
LLM可以通过对大量文本和代码的训练来做到这一点,然后可以使用这些知识来生成新的文本、翻译语言、编写不同类型的创意内容,并以信息丰富的方式回答您的问题。搜索引擎的工作方式不同,它会搜索互联网上已存在的文本,并将最相关的文本返回给您。
- 交互方式和交互次数不同
LLM是与用户交互的,可以通过文本或语音输入来进行对话。用户可以连续与模型进行交互,获得多轮对话的结果。可以按用户的需求进行汇总、整理和输出。
搜索引擎一般是单向的,用户输入查询后,会得到一个结果页面,而无法进行后续的交互。
- 数据处理和输出方式不同
LLM在输出时通常会生成一段完整的自然语言文本,回答问题或提供信息。
搜索引擎的输出是一个包含相关网页链接的列表,用户可以通过点击链接来访问相关的网页内容。
LLM 可以理解主义再输出结果,搜索引擎只能匹配关键词
- 数据处理及结果不同
LLM 由一定规模人工校检过的数据训练而成,数据有延迟,但精度高。搜索引擎只索引数据,没有经过人工标注,数据实时性更好。
两者都是建立在大规模的数据上,但 LLM 对干净、准确的数据要求更高。
常见术语
| 英文 | 中文 | 含义 |
|---|---|---|
| LLM | 大型语言模型 | Large language model,一种神经网络模型,在大量文本数据上进行训练,能够生成文本、翻译语言、编写不同类型的创意内容,并以信息丰富的方式回答您的问题。 |
| Parameter | 参数 | 在神经网络中,参数是模型学习的变量,控制模型的输出。 |
| Weights | 权重 | 参数的一种类型,控制模型中不同特征的重要性。 |
| Bias | 偏差 | 参数的一种类型,控制模型的输出偏差。 |
| Training | 训练 | 大型语言模型的过程,包括向模型提供大量文本数据并使其学习识别文本中模式。 |
| Evaluation | 评估 | 大型语言模型的过程,包括使用测试数据集来衡量模型的性能。 |
| Deployment | 部署 | 大型语言模型的过程,使其可用于用户。 |
| Fine-tuning | 微调 | 对大型语言模型进行额外的训练,以提高其在特定任务上的性能。 |
| Transfer learning | 迁移学习 | 使用大型语言模型在一个任务上学习到的知识,以提高其在另一个任务上的性能。 |
| Zero-shot learning | 零样本学习 | 没有任何标记数据的情况下,学习执行任务的能力。 |
| Common sense | 常识 | 关于世界的基本知识,例如物体、事件和关系。 |
| Reasoning | 推理 | 使用常识来得出结论或做出决定的能力。 |
| Creativity | 创造力 | 生成新颖和有创意的内容的能力。 |
| Open-endedness | 开放性 | 能够处理和响应开放式提示和问题的能力。 |
| Fluency | 流畅性 | 生成自然和流畅文本的能力。 |
| Accuracy | 准确性 | 生成正确和准确文本的能力。 |
| Diversity | 多样性 | 生成不同文本格式的能力,如诗歌、代码、脚本、音乐作品、电子邮件、信件等。 |
| Relevance | 相关性 | 生成与查询相关文本的能力。 |
| Coherence | 连贯性 | 生成连贯和一致文本的能力。 |
| Completeness | 完整性 | 生成全面和完整文本的能力。 |
| Informational | 信息性 | 生成有用和信息丰富文本的能力。 |
| Clarity | 清晰度 | 生成清晰易懂文本的能力。 |
| Objectivity | 客观性 | 生成不带偏见和客观文本的能力。 |
| Fairness | 公平性 | 生成不歧视和公平文本的能力。 |
| Privacy | 隐私性 | 保护用户隐私的能力。 |
| Security | 安全性 | 防止攻击和滥用的能力。 |
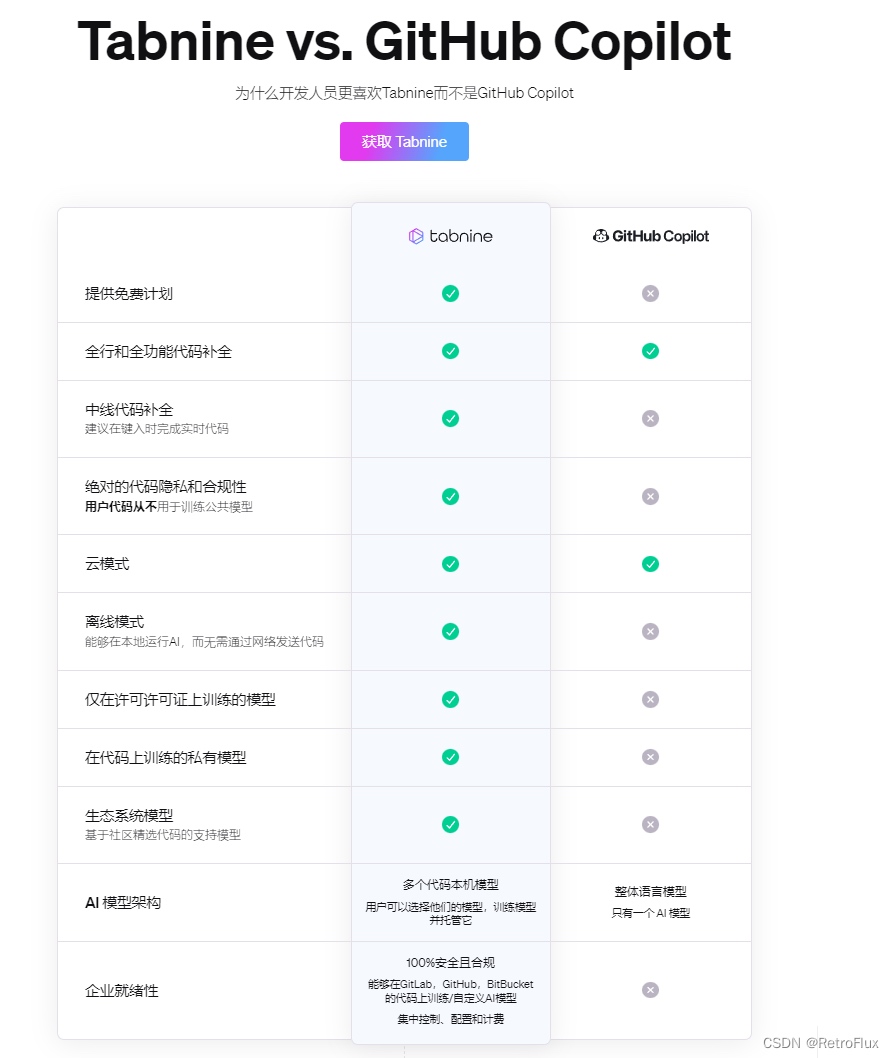
程序员专享之 IDE 代码生成插件对比